Two weeks ago, we tasked Kyle from our Research and Development team with covering some common themes discussed at Black Hat and DEF CON. We want to bring these issues to both the security community that was in Vegas at the cons and those who kept an eye on the action from the outside.
I started this series with a grumpy discussion of the use and potential misuse of deep learning, i.e., neural networks. Today, I want to wrap this series up with discussion of some machine learning presentations that were encouraging. As we take a look at the future of the field, we’re going to fly through background discussions, so if you’re interesting in taking the scenic route, be sure to check out the linked material.
Defeating Machine Learning: What Your Security Vendor Isn’t Telling You
Bob Klein and Ryan Peters of BluVector demonstrated at DEF CON a major flaw in machine-learning based malware detection: practically static models. A hand-wavy explanation of models is that they’re sets of configuration options and values of variables in equations. A common workflow is your vendor training their model in its lab to distinguish between malicious and benign programs and then shipping the model data to customers as an update.
Klein and Peters demonstrated that, with a copy of the model from an update but not the training data, an attacker could defeat the still model quickly, relative to the pace of updates. In their demo, they were able to modify a malicious program such that it still worked but also got past the detector. It took 1,900 iterations, which is slower than defeating antivirus but still considered fast if compared to the update frequency.
The speakers’ solution boils down to creating a “moving defense.” They proposed a workflow where vendors provide a base model, but customers then customize it for their environment by providing two types of new information: programs that were mislabeled with the correct label and some of the malware that the customer actually sees coming at them. This results in every model being different, and thus dodging one customer’s model no longer means that you can just use the same malware for everyone using the product. Having the model continue to learn after deployment creates a sort of herd immunity rather than a bunch of bananas that are extremely vulnerable due to identical DNA.
Why Security Data Science Matters and How It’s Different
Joshua Saxe of Invincea gave a double-header talk at Black Hat about security data science, in an effort to bridge the gap between the security community and the data science community. He sums up the need for data science as: “we have access to the signals needed to detect attackers, but they are currently the ‘dark matter’ of our field.” The useful information is hidden in terabytes of logs, hundreds of millions of malware samples that have never been analyzed, and so on. Attacks are relatively rare, compared to legitimate usage. For a threat detection system to be useful to security operations teams, the false positive rate needs to be very low, since a higher false positive rate times the volume of legitimate opportunities to falsely label as malicious equals an overwhelming number of false positives for security teams to sort through.
Saxe presented the details of three customer stories his team has tackled. The first customer story described their work modelling componentization of malware components. At first, I was nervous that they used “deep learning”—a neural network with just two hidden layers—given my complaints about it earlier. Saxe quickly addressed my concerns by discussing other methods they tried with no success and, most importantly in my eyes, presenting an ROC curve. The short version is that a ROC curve lets you pick the highest false positive rate that you’re willing to accept, and you can see how many of the known-positives your algorithm will correctly identify. Their ROC curve shows that their neural network can detect 95% of zero-days with a 0.1% false-positive rate, which is quite impressive and possibly the best results that have been published. These results definitely feel too good to be true. From the perspective of a trained scientist, they should release the details of their algorithm and their dataset so that anyone can reproduce their results, but surely Invincea considers that proprietary and understandably so. As such, we do have to take their word for it. It’d be interesting to see how this performs on entirely different datasets and whether or not other entities are able to produce similar results independently.
I was also particularly interested in the third customer story, in which their tool, Cynomix (in private beta), performs automatic capability recognition of malware samples to aid reverse engineers. Cynomix is designed to identify similar code blocks based, at least partially, on function calls within a given code block. Since there are only so many ways one can program low-level tasks, like opening a network socket, their tool leverages code posted on StackOverflow for capability identification. Once similar code segments have been found, the keywords on the StackOverflow page can be used to predict the purpose of the given code segment.
Cynomix can also apply the code-matching algorithms to identify malware families based on code re-use:

Note that the piece of unrelated malware clearly stands out, because it has minimal code reuse from the family, so the Cynomix does the best it can, but it’s clearly not following the same patterns as the rest.
Overall, this talk has a lot of value to both the security and data communities. I already do some data science stuff as part of my job (though I just call it “stats and graphs and sh*t”), but this talk has inspired me to learn more data visualization techniques and tools. Saxe demonstrated the power of visualization through the conclusions his team was able to reach beyond “this is a pretty picture.”
Saxe’s slides go into much more detail and also have pretty pictures.
From False Positives to Actionable Analysis
Joseph Zadeh of Splunk presented at Black Hat about his vision for the future of security operations. He discussed a model for taking action based on low-hanging-but-high-ROI fruit. We often try to model and protect against the complex and novel adversaries when, really, there are better returns to be had with less effort, such as detecting web server reconnaissance or pseudorandom domain detection:
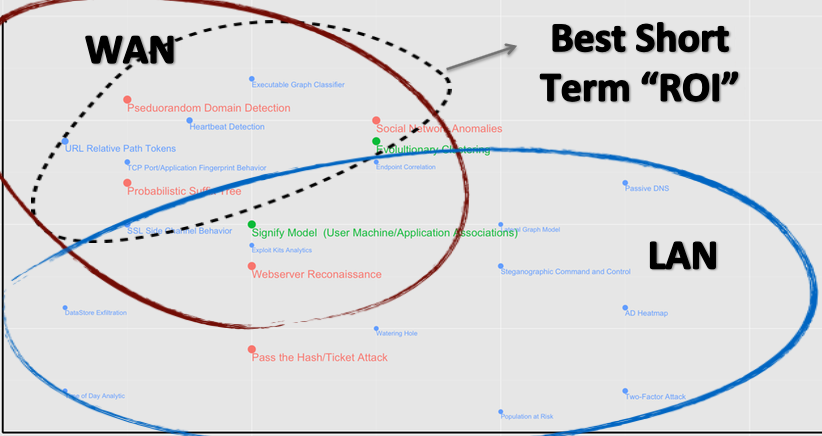
In building defenses, Zadeh advocates for a “central nervous system” model, where we advance beyond reacting to single signals—an IDS alert, for example—and instead consider a wide variety of sensors as a whole, similar to how our biological brains process information. As we deal with an increasing volume of data and traffic, we’re rapidly approaching the point where security operations teams are bogged down by a flood of low level data without any sort of analysis provided.
Zadeh tied this “central nervous system” in with a discussion of lambda architectures, a concept developed by Nathan Marz. The short version is that it’s a genericization of reinforcement learning, as discussed earlier. A lambda architecture starts with batch analysis of archived data, and then combines that with real-time analysis to continually refine whatever black box produces the output of the system. As with the malware-detection problem above, given the rapid pace of security attack development, relying on static models and rules becomes ineffective when faced with even a moderately skilled attacker.
I appreciated the forward-looking nature as a definite contrast to the talks that just presented attacks. The discussion of security ROI is an important one. I chatted with Zadeh afterward about the importance of connecting security operations and research with the business’s interests. His experience was that of frequent disconnects between the different components, which results in the technical groups going after low-ROI targets instead of the attacks that are quick to address and much more common. It’s unclear how many more major breaches it will take to change the prioritization of the security community, but, for all of our sakes, I hope we’ve already started to reconsider where we direct our efforts.
Zadeh’s slides and Splunk’s whitepaper are available from Black Hat.
So, What Does This All Mean?
Machine learning is not a panacea for security problems, though it certainly is a hot topic in the community that deserves ongoing attention and research. That said, machine learning techniques can enable a much more comprehensive defense, especially the approach called a “moving defense” or “moving target”, where models and rules are dynamically updated based on what’s actually going on and attacking the network in question. The model of a “central nervous system” of indicators and analyzers definitely has potential to provide a much more comprehensive defense solution to help security operations teams work on protecting against actual threats rather than trudging through piles of false positives.